Loading... # 一 配置模型 ## 1、获取本地模型名称 ``` ollama list ```  ## 2、配置ollama中的LLM模型 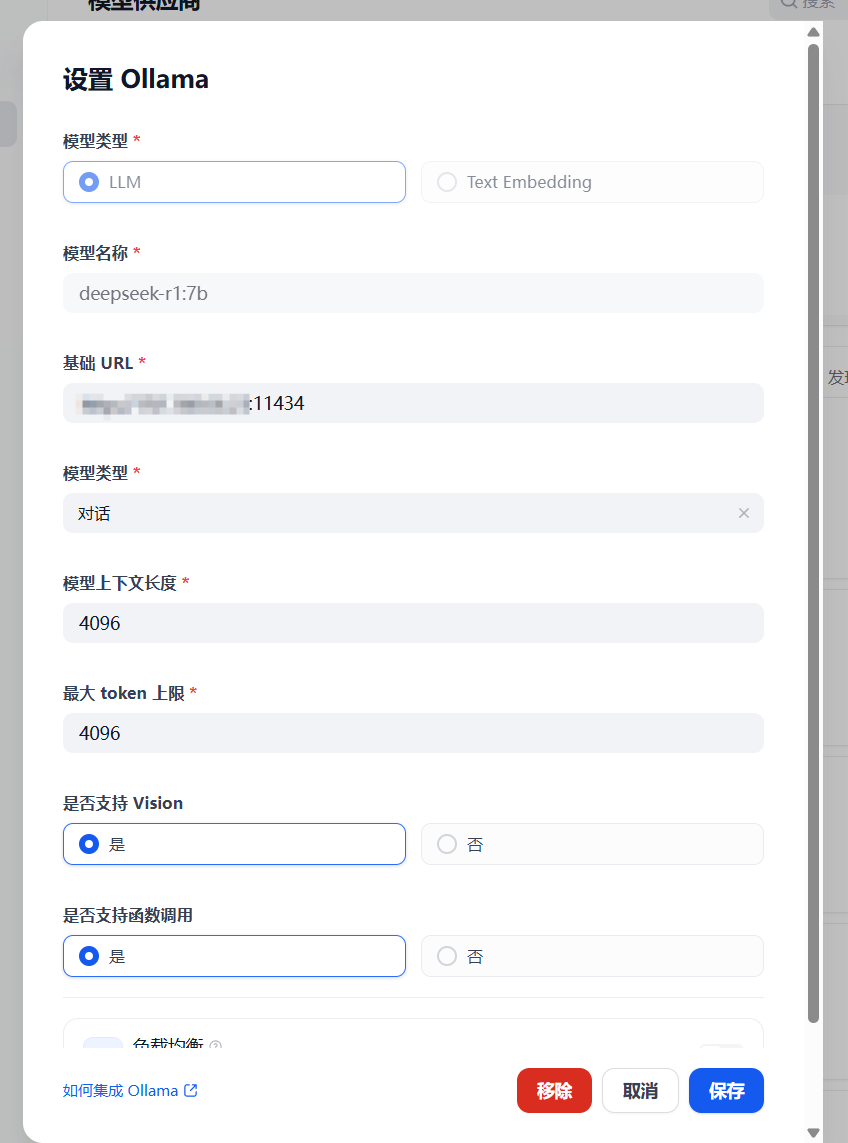 ## 3、配置Text Embedding 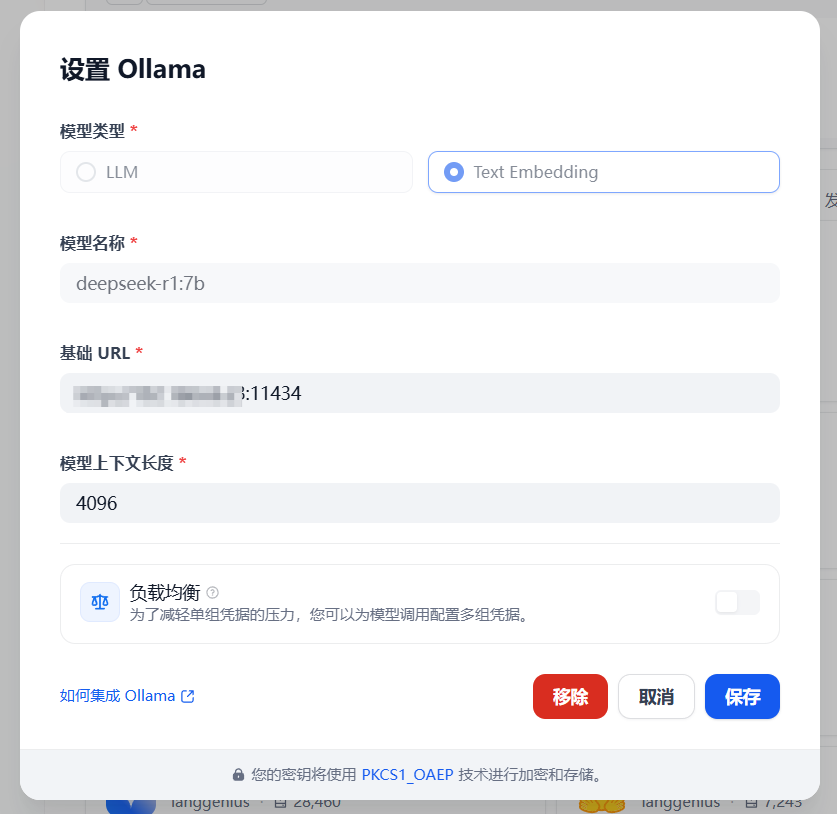 ## 3、大语言模型(LLM)部署和推理工具——**Xinference** ``` docker pull xprobe/xinference:latest docker run -p 9997:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0 ``` [Xinference教程](https://zhuanlan.zhihu.com/p/685224526) 启动后可以通过`http://localhost:9997`访问 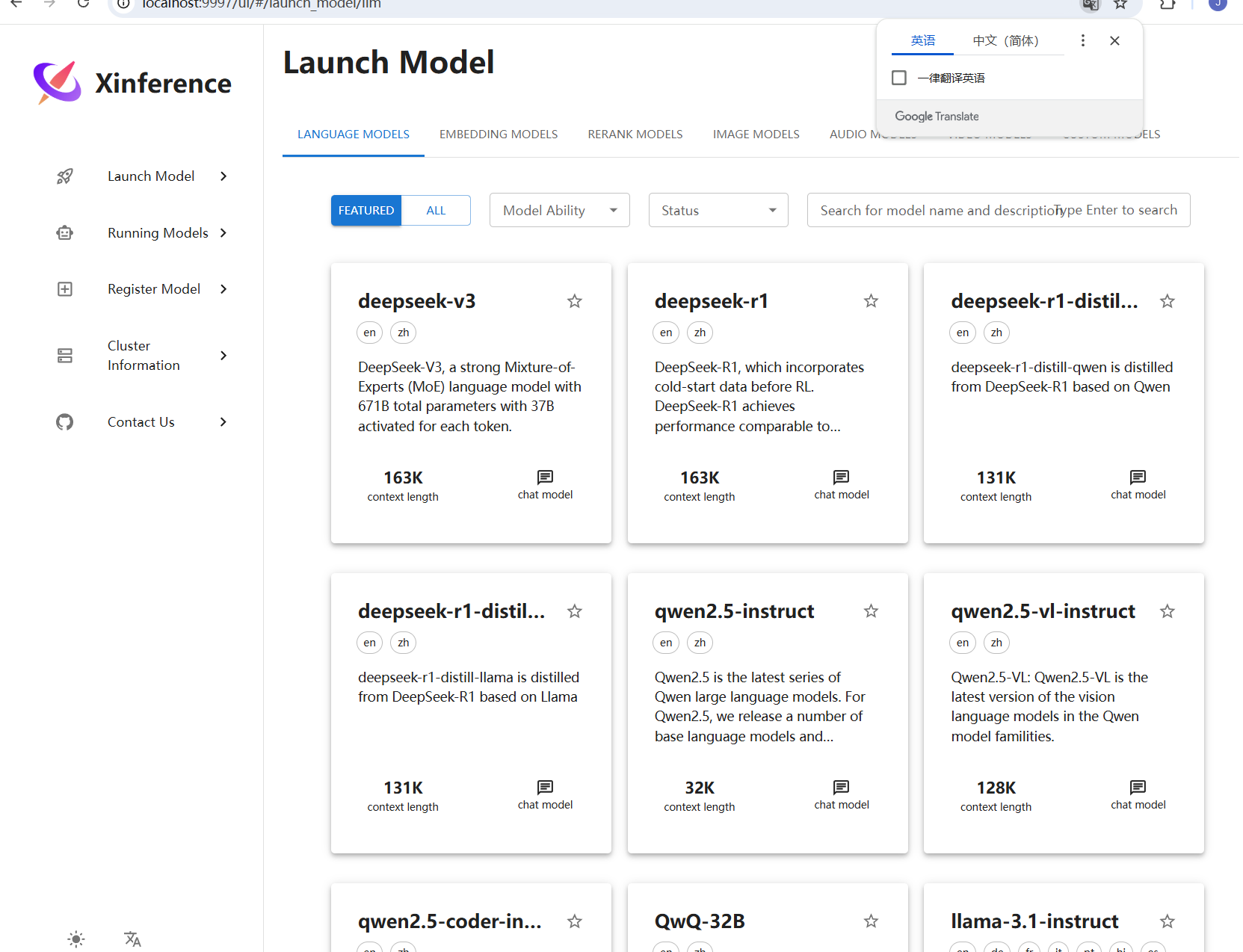 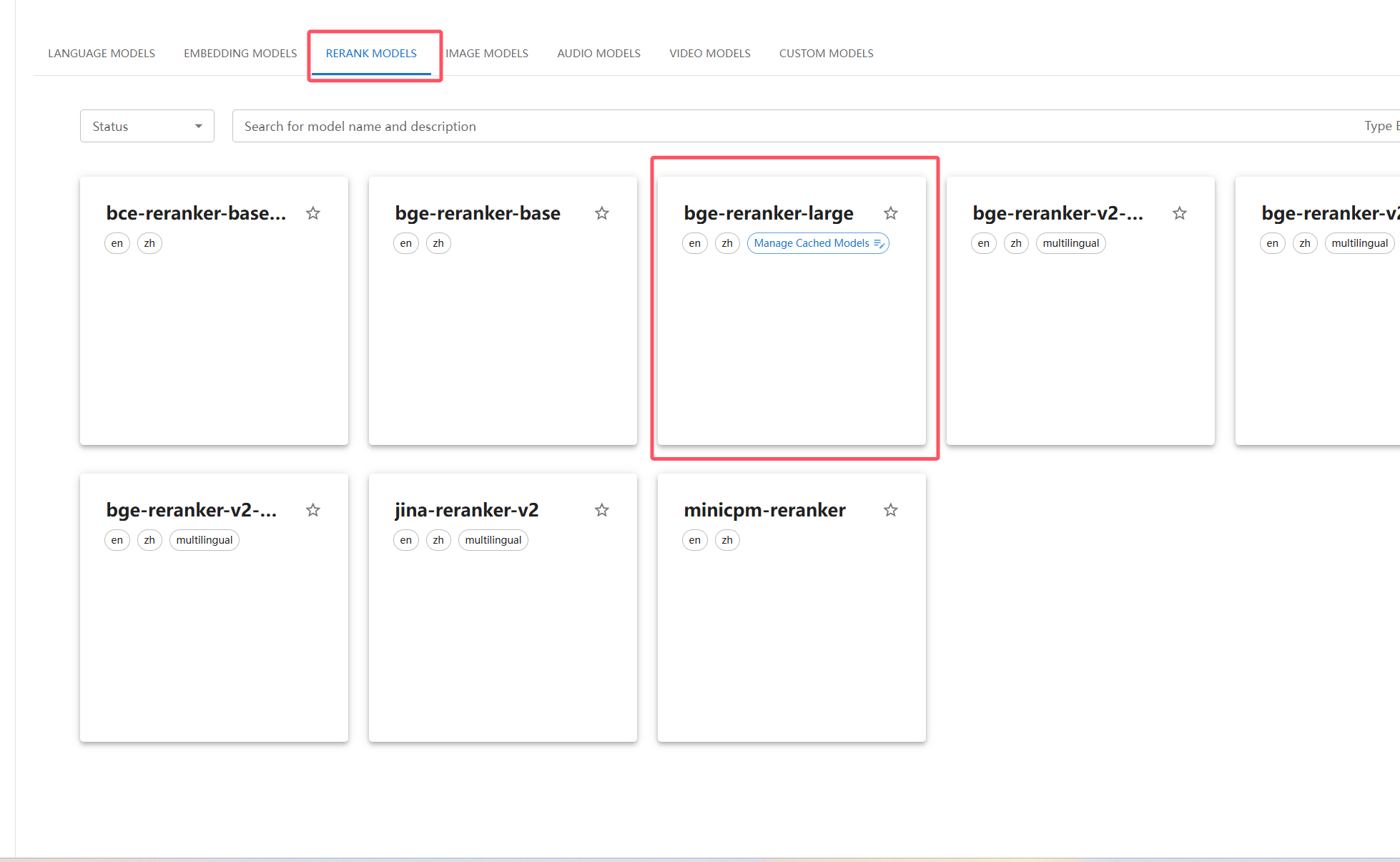 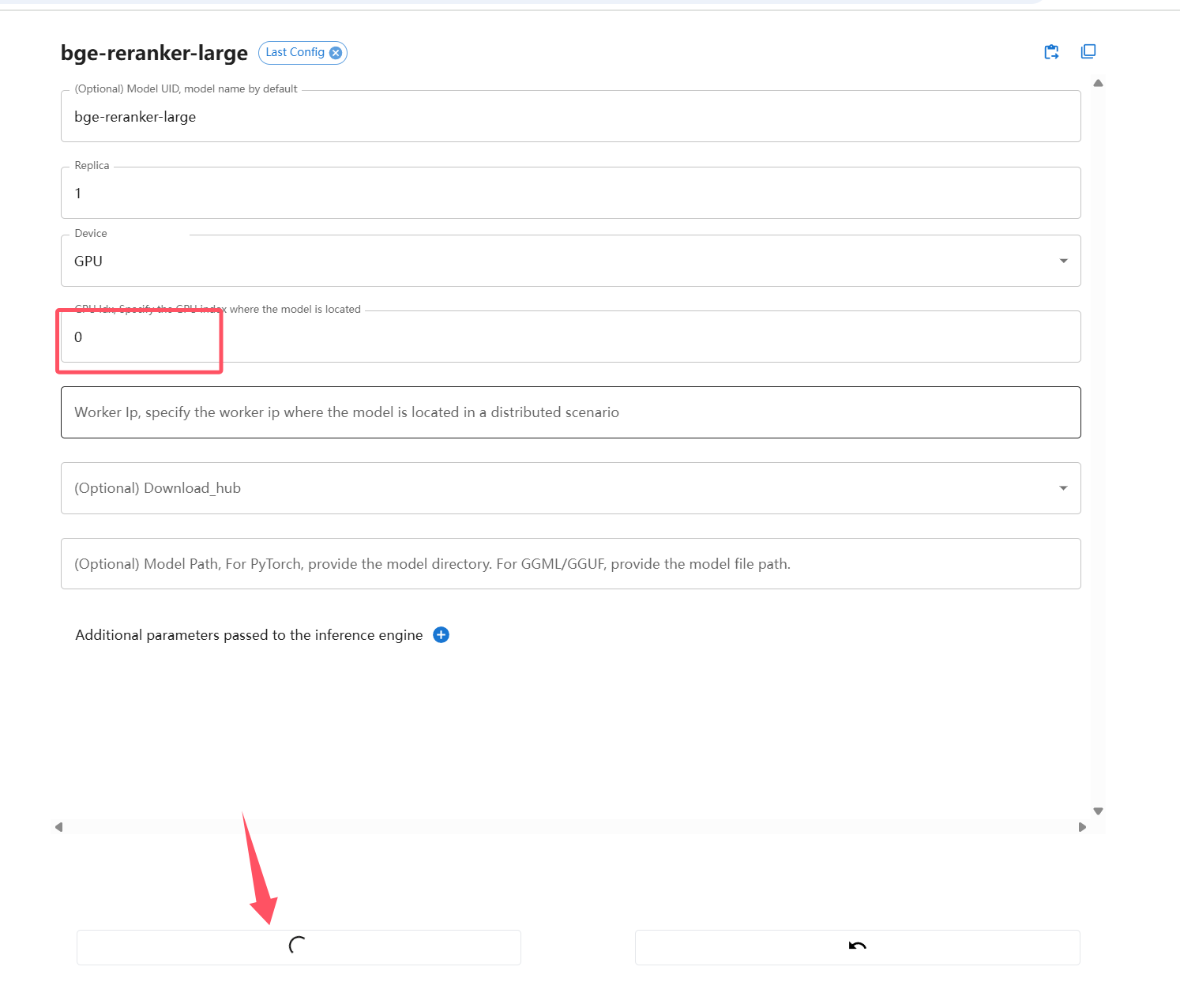 GPUidx 一半都是填0,如果有多个gpu可以用逗号隔开如0、1  安装插件`Xorbits Inference`  在本地dify中配置 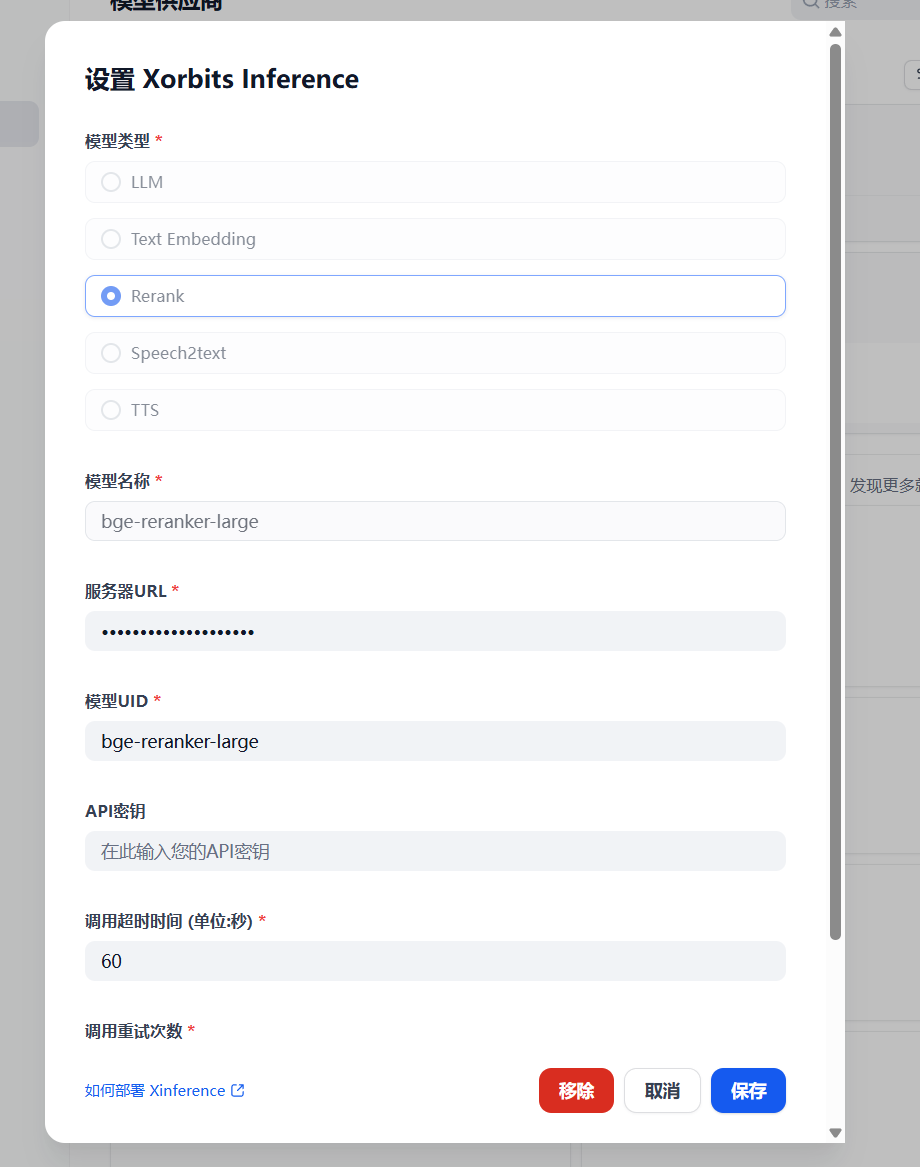 # 二 搭建知识库 打开本地部署的Dify网站。 ## 1、点击知识库菜单,点击创建知识库 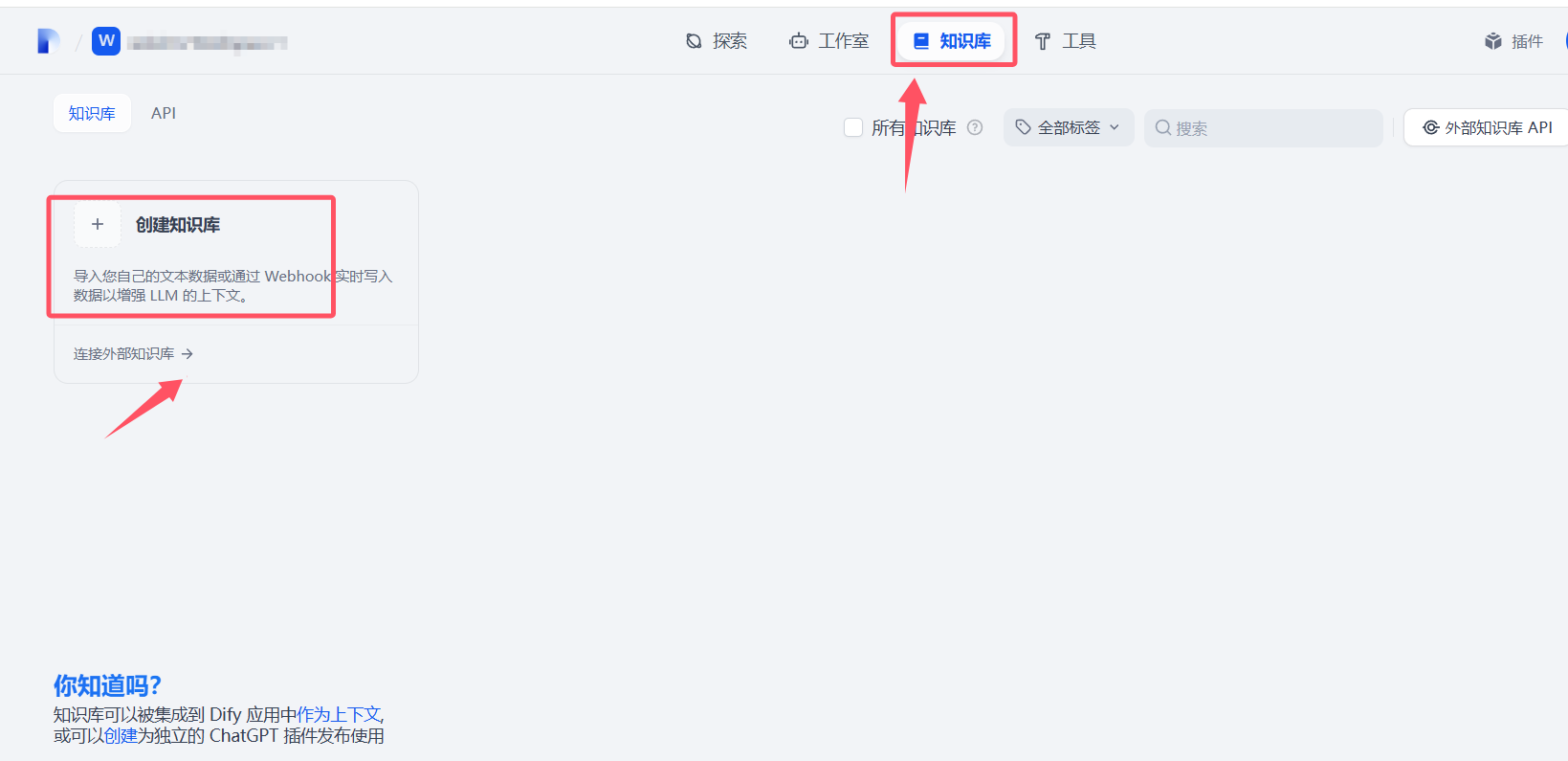 ## 2、上传本地知识库,这里选择上传本地文件 ## 3、知识库配置 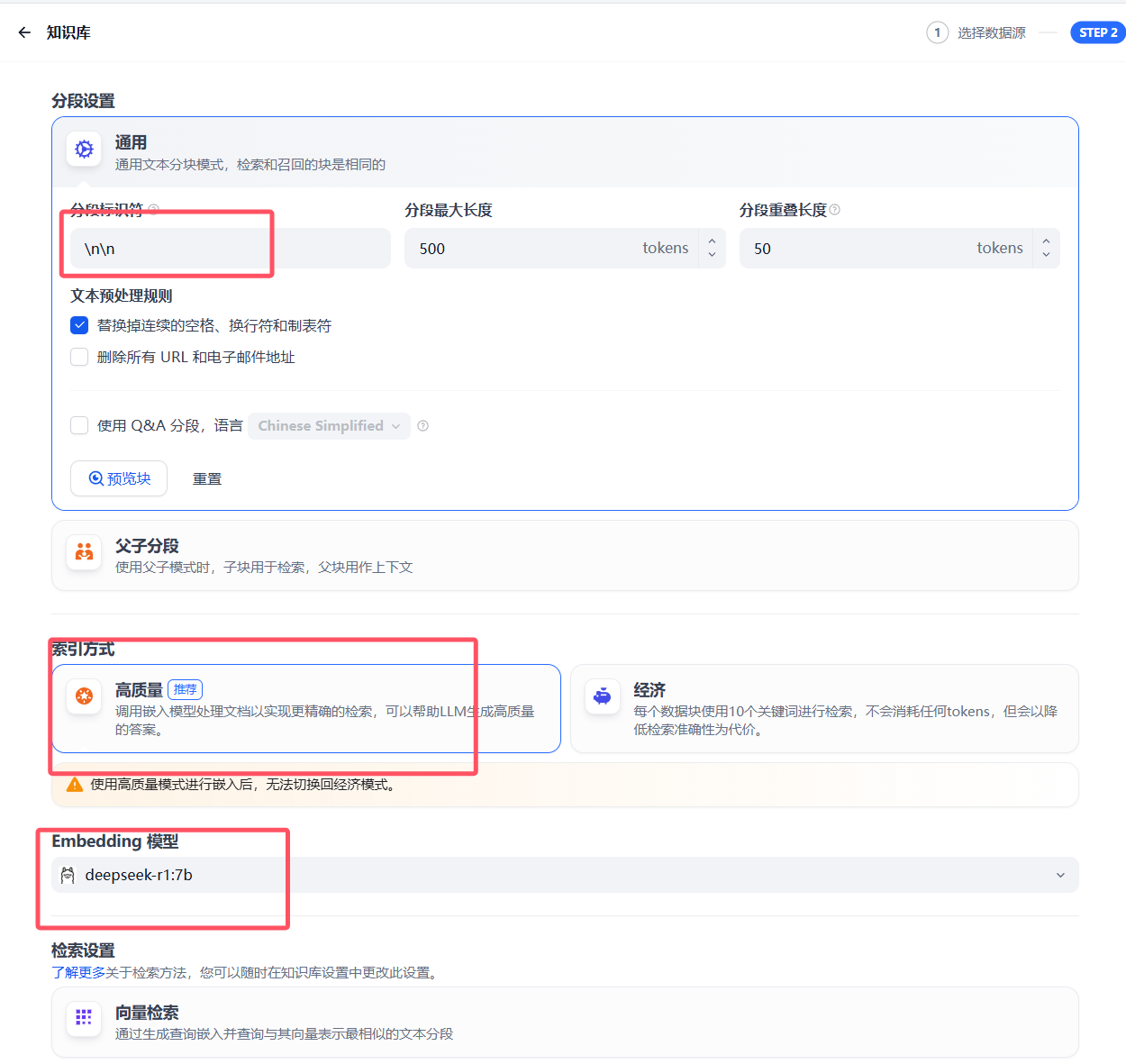 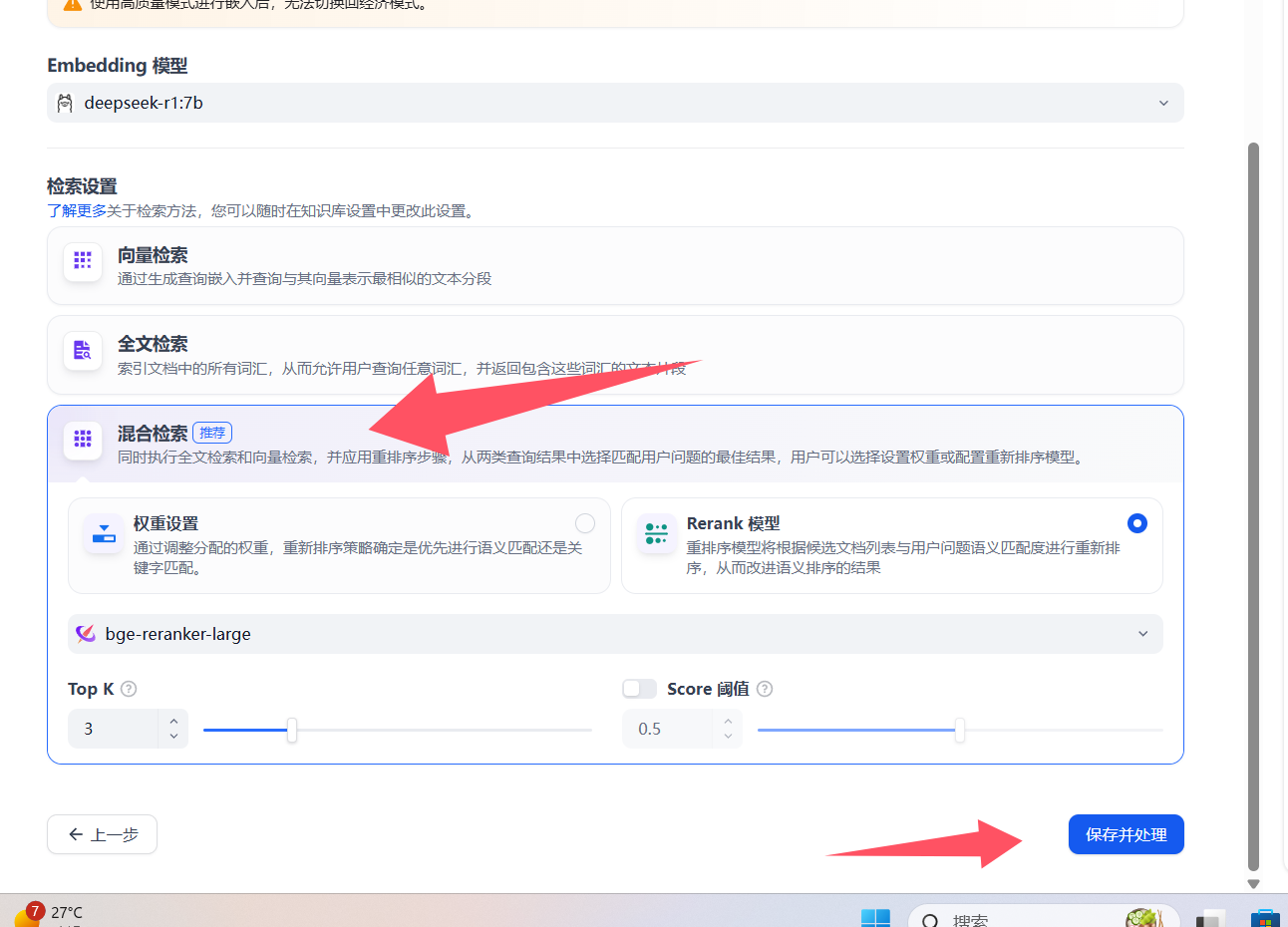 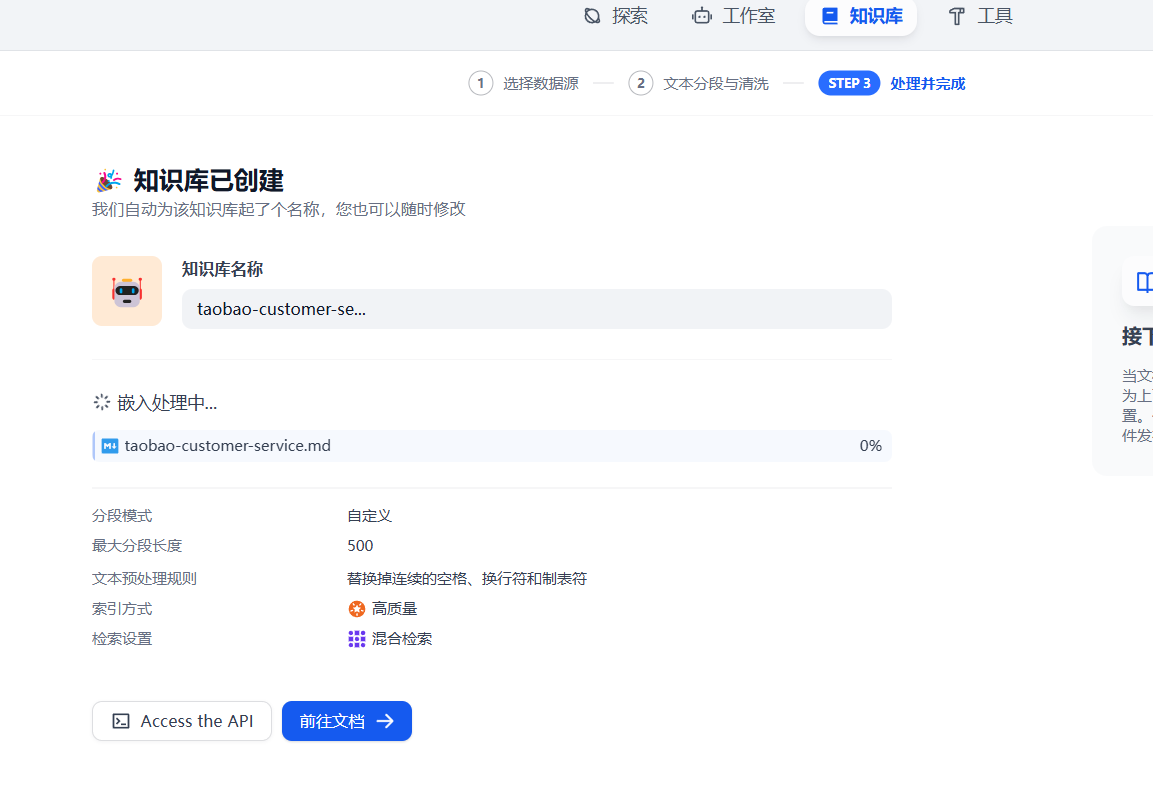 完成 最后修改:2025 年 04 月 16 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
