Loading... <div class="tip inlineBlock error"> ipynb文件格式:[7.pandas对缺失值的处理.html](http://type.zimopy.com/usr/uploads/2022/12/669445859.html) </div> 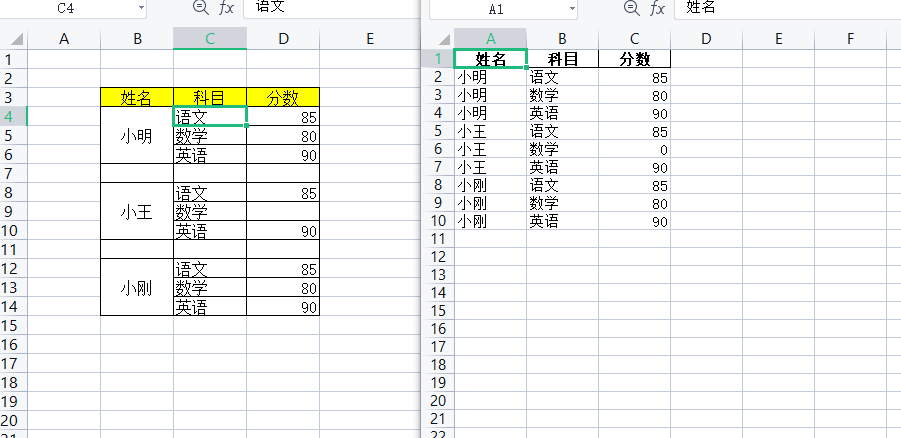 左边是未清洗,右边是清洗后的 下面开始清洗 # pandas对缺失值的处理 Pandas使用这些函数处理缺失值: * isnull和notnull:检测是否是空值,可用于df和series * dropna:丢弃、删除缺失值 - axis : 删除行还是列,{0 or ‘index’, 1 or ‘columns’}, default 0 - how : 如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除 - inplace : 如果为True则修改当前df,否则返回新的df * fillna:填充空值 - value:用于填充的值,可以是单个值,或者字典(key是列名,value是值) - method : 等于ffill使用前一个不为空的值填充forword fill;等于bfill使用后一个不为空的值填充backword fill - axis : 按行还是列填充,{0 or ‘index’, 1 or ‘columns’} - inplace : 如果为True则修改当前df,否则返回新的df ```python import pandas as pd ``` # 实例:特殊excel的读取、清洗、处理 # 步骤1:读取excel时,忽略前几个空行 ```python studf = pd.read_excel("../datas/student_excel/student_excel.xlsx",skiprows=2) ``` ```python studf ``` <div> <style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; } </style> <table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>Unnamed: 0</th> <th>姓名</th> <th>科目</th> <th>分数</th> </tr> </thead> <tbody> <tr> <th>0</th> <td>NaN</td> <td>小明</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>1</th> <td>NaN</td> <td>NaN</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>2</th> <td>NaN</td> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>3</th> <td>NaN</td> <td>NaN</td> <td>NaN</td> <td>NaN</td> </tr> <tr> <th>4</th> <td>NaN</td> <td>小王</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>5</th> <td>NaN</td> <td>NaN</td> <td>数学</td> <td>NaN</td> </tr> <tr> <th>6</th> <td>NaN</td> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>7</th> <td>NaN</td> <td>NaN</td> <td>NaN</td> <td>NaN</td> </tr> <tr> <th>8</th> <td>NaN</td> <td>小刚</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>9</th> <td>NaN</td> <td>NaN</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>10</th> <td>NaN</td> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> </tbody> </table> </div> # 步骤2:检测空值 ## 检测所有 ```python studf.isnull() ``` <div> <style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; } </style> <table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>Unnamed: 0</th> <th>姓名</th> <th>科目</th> <th>分数</th> </tr> </thead> <tbody> <tr> <th>0</th> <td>True</td> <td>False</td> <td>False</td> <td>False</td> </tr> <tr> <th>1</th> <td>True</td> <td>True</td> <td>False</td> <td>False</td> </tr> <tr> <th>2</th> <td>True</td> <td>True</td> <td>False</td> <td>False</td> </tr> <tr> <th>3</th> <td>True</td> <td>True</td> <td>True</td> <td>True</td> </tr> <tr> <th>4</th> <td>True</td> <td>False</td> <td>False</td> <td>False</td> </tr> <tr> <th>5</th> <td>True</td> <td>True</td> <td>False</td> <td>True</td> </tr> <tr> <th>6</th> <td>True</td> <td>True</td> <td>False</td> <td>False</td> </tr> <tr> <th>7</th> <td>True</td> <td>True</td> <td>True</td> <td>True</td> </tr> <tr> <th>8</th> <td>True</td> <td>False</td> <td>False</td> <td>False</td> </tr> <tr> <th>9</th> <td>True</td> <td>True</td> <td>False</td> <td>False</td> </tr> <tr> <th>10</th> <td>True</td> <td>True</td> <td>False</td> <td>False</td> </tr> </tbody> </table> </div> ## 检测单列 ```python # studf["分数"].notnull()#不为空 studf["分数"].isnull()#为空 ``` 0 False 1 False 2 False 3 True 4 False 5 True 6 False 7 True 8 False 9 False 10 False Name: 分数, dtype: bool ## 筛选没有空分数的所有行 ```python studf.loc[studf["分数"].notnull(),:] ``` <div> <style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; } </style> <table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>Unnamed: 0</th> <th>姓名</th> <th>科目</th> <th>分数</th> </tr> </thead> <tbody> <tr> <th>0</th> <td>NaN</td> <td>小明</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>1</th> <td>NaN</td> <td>NaN</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>2</th> <td>NaN</td> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>4</th> <td>NaN</td> <td>小王</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>6</th> <td>NaN</td> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>8</th> <td>NaN</td> <td>小刚</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>9</th> <td>NaN</td> <td>NaN</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>10</th> <td>NaN</td> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> </tbody> </table> </div> # 步骤3:删除全是空值的列 ```python studf.dropna(axis="columns",how="all",inplace=True) studf ``` <div> <style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; } </style> <table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>姓名</th> <th>科目</th> <th>分数</th> </tr> </thead> <tbody> <tr> <th>0</th> <td>小明</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>1</th> <td>NaN</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>2</th> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>3</th> <td>NaN</td> <td>NaN</td> <td>NaN</td> </tr> <tr> <th>4</th> <td>小王</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>5</th> <td>NaN</td> <td>数学</td> <td>NaN</td> </tr> <tr> <th>6</th> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>7</th> <td>NaN</td> <td>NaN</td> <td>NaN</td> </tr> <tr> <th>8</th> <td>小刚</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>9</th> <td>NaN</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>10</th> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> </tbody> </table> </div> # 步骤4:删除全是空值的行 ```python studf.dropna(axis="index",how="all",inplace=True) studf ``` <div> <style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; } </style> <table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>姓名</th> <th>科目</th> <th>分数</th> </tr> </thead> <tbody> <tr> <th>0</th> <td>小明</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>1</th> <td>NaN</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>2</th> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>4</th> <td>小王</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>5</th> <td>NaN</td> <td>数学</td> <td>NaN</td> </tr> <tr> <th>6</th> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>8</th> <td>小刚</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>9</th> <td>NaN</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>10</th> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> </tbody> </table> </div> # 步骤5:将分数列为空的填充为0分 ```python studf.fillna({"分数":0},inplace=True) # 等同于 # studf.loc[;,"分数"] = studf["分数"].fillna(0) ``` ```python studf ``` <div> <style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; } </style> <table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>姓名</th> <th>科目</th> <th>分数</th> </tr> </thead> <tbody> <tr> <th>0</th> <td>小明</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>1</th> <td>NaN</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>2</th> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>4</th> <td>小王</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>5</th> <td>NaN</td> <td>数学</td> <td>0.0</td> </tr> <tr> <th>6</th> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>8</th> <td>小刚</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>9</th> <td>NaN</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>10</th> <td>NaN</td> <td>英语</td> <td>90.0</td> </tr> </tbody> </table> </div> # 步骤6:将姓名的缺失值填充 使用前面的有效值填充,用ffill:forward fill ```python studf.loc[:,"姓名"] = studf["姓名"].fillna(method = "ffill") studf ``` <div> <style scoped> .dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; } </style> <table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>姓名</th> <th>科目</th> <th>分数</th> </tr> </thead> <tbody> <tr> <th>0</th> <td>小明</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>1</th> <td>小明</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>2</th> <td>小明</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>4</th> <td>小王</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>5</th> <td>小王</td> <td>数学</td> <td>0.0</td> </tr> <tr> <th>6</th> <td>小王</td> <td>英语</td> <td>90.0</td> </tr> <tr> <th>8</th> <td>小刚</td> <td>语文</td> <td>85.0</td> </tr> <tr> <th>9</th> <td>小刚</td> <td>数学</td> <td>80.0</td> </tr> <tr> <th>10</th> <td>小刚</td> <td>英语</td> <td>90.0</td> </tr> </tbody> </table> </div> # 步骤7:将洗好的excel保存 ```python studf.to_excel("../datas/student_excel/student_excel_clean.xlsx",index=False) ``` 使用的数据集: <div class="hideContent">此处内容需要评论回复后(审核通过)方可阅读。</div> 最后修改:2022 年 12 月 15 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
