Loading... # 第一种 : **pandas删除DataFrame中某列值为NaN的记录/行** ```python import pandas as pd import numpy as np input_rows = [[1,2,3], [2,3,4], [np.nan, 2, np.nan, 5], [np.nan, 5, 7]] df = pd.DataFrame(input_rows, columns=['a', 'b', 'c', 'd']) ``` 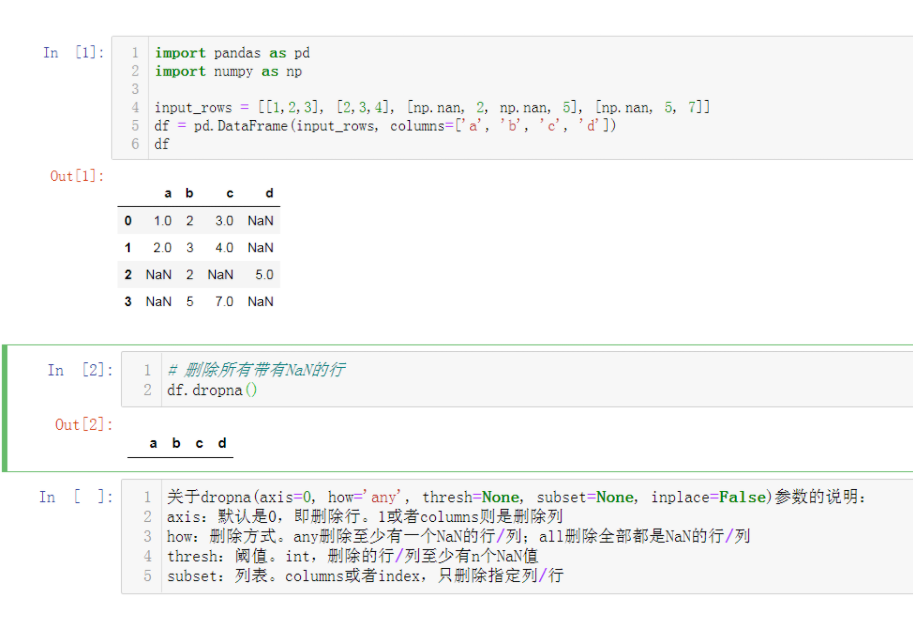 ## 1.过滤某一列没有nan的数据。~取反  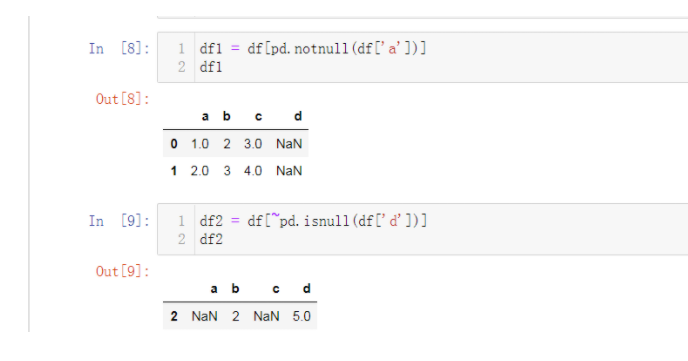 ## 2.使用[numpy](https://so.csdn.net/so/search?q=numpy&spm=1001.2101.3001.7020).isnan 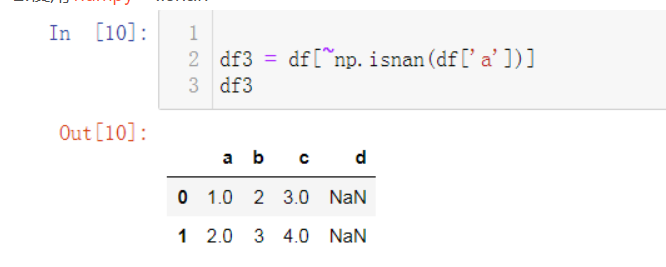 ## 3.使用query 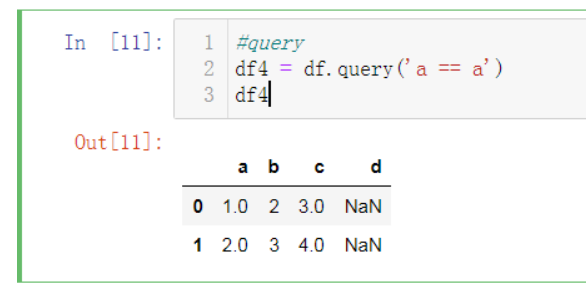 # pandas中关于nan的处理 在pandas中有个另类的存在就是nan,解释是:not a number,不是一个数字,但是它的类型确是一个float类型。numpy中也存在关于nan的方法,如:np.nan 对于pandas中nan的处理,简单的说有以下几个方法。 查看是否是nan, s1.isnull() 和 s1.notnull() 丢弃有nan的索引项,s1.dropna() 将nan填充为其他值,df2.fillna() ```python import numpy as np import pandas as pd from pandas import Series, DataFrame n = np.nan print(type(n)) # <class 'float'> m = 1 print(n+m) # nan 任何数字和nan进行计算,都是nan # nan in series s1 = Series([1, 2, np.nan, 3, 4], index=['A', 'B', 'C', 'D', 'E']) print(s1) ''' A 1.0 B 2.0 C NaN D 3.0 E 4.0 dtype: float64 ''' print(s1.isnull()) # 返回 bool值,是 nan 的话,返回true ''' A False B False C True D False E False dtype: bool ''' print(s1.notnull()) # 非 nan , 返回true ''' A True B True C False D True E True dtype: bool ''' # 去掉 有 nan 的索引项 print(s1.dropna()) ''' A 1.0 B 2.0 D 3.0 E 4.0 dtype: float64 ''' # nan in dataframe df = DataFrame([[1, 2, 3], [np.nan, 5, 6], [7, np.nan, 9], [np.nan, np.nan, np.nan]]) print(df) ''' 0 1 2 0 1.0 2.0 3.0 1 NaN 5.0 6.0 2 7.0 NaN 9.0 3 NaN NaN NaN ''' print(df.isnull()) # df.notnull() 同理 ''' 0 1 2 0 False False False 1 True False False 2 False True False 3 True True True ''' # 去掉 所有 有 nan 的 行, axis = 0 表示 行方向 df1 = df.dropna(axis=0) print(df1) ''' 0 1 2 0 1.0 2.0 3.0 ''' # 表示在 列 的方向上。 df1 = df.dropna(axis=1) print(df1) ''' mpty DataFrame Columns: [] Index: [0, 1, 2, 3] ''' # any 只要有 nan 就会删掉。 all 是必须全是nan才删除 df1 = df.dropna(axis=0, how='any') print(df1) ''' 0 1 2 0 1.0 2.0 3.0 ''' # any 只要有 nan 就会删掉。 all 全部是nan,才会删除 df1 = df.dropna(axis=0, how='all') print(df1) ''' 0 1 2 0 1.0 2.0 3.0 1 NaN 5.0 6.0 2 7.0 NaN 9.0 ''' df2 = DataFrame([[1, 2, 3, np.nan], [2, np.nan, 5, 6], [np.nan, 7, np.nan, 9], [1, np.nan, np.nan, np.nan]]) print(df2) ''' 0 1 2 3 0 1.0 2.0 3.0 NaN 1 2.0 NaN 5.0 6.0 2 NaN 7.0 NaN 9.0 3 1.0 NaN NaN NaN ''' print(df2.dropna(thresh=None)) ''' Empty DataFrame Columns: [0, 1, 2, 3] Index: [] ''' print(df2.dropna(thresh=2)) # thresh 表示一个范围,如:每一行的nan > 2,就删除 ''' 0 1 2 3 0 1.0 2.0 3.0 NaN 1 2.0 NaN 5.0 6.0 2 NaN 7.0 NaN 9.0 ''' # 将nan进行填充 print(df2.fillna(value=1)) ''' 0 1 2 3 0 1.0 2.0 3.0 1.0 1 2.0 1.0 5.0 6.0 2 1.0 7.0 1.0 9.0 3 1.0 1.0 1.0 1.0 ''' # 可以 为指定列 填充不同的 数值 print(df2.fillna(value={0: 0, 1: 1, 2: 2, 3: 3})) # 指定每一列 填充的数值 ''' 0 1 2 3 0 1.0 2.0 3.0 3.0 1 2.0 1.0 5.0 6.0 2 0.0 7.0 2.0 9.0 3 1.0 1.0 2.0 3.0 ''' # 以下两个例子需要说明的是:对dataframe进行dropna,原来的dataframe不会改变 print(df1.dropna()) ''' 0 1 2 0 1.0 2.0 3.0 ''' print(df1) ''' 0 1 2 0 1.0 2.0 3.0 1 NaN 5.0 6.0 2 7.0 NaN 9.0 ''' ``` 最后修改:2023 年 02 月 02 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
