Loading... # 抓包工具_mitmdump使用 ## 1、mitmdump介绍 * mitmdump是mitmprxoy的命令行接口,可以实时监控请求,可以对接Python对请求进行处理 * 有了它我们可以不用手动截获和分析HTTP请求和响应,只需要写好请求和响应的处理逻辑即可 * 它还可以实现数据的解析、存储等工作,这些过程都可以通过Python实现 * [mitmproxy安装及设置](https://blog.csdn.net/weixin_43411585/article/details/89211823) * [官方文档](https://docs.mitmproxy.org/stable/tools-mitmdump/) ## 2、mitmdump_python脚本修改请求 ① 先准备一个py文件如scripts.py:如对请求的改写,定义了一个request()方法,参数为flow(HTTPFlow对象),通过flow.request属性即可获取到当前的请求对象,然后打印输出了请求的请求头,如将请求头的User-Agent修改成了MitmProxy ```python #scripts.py文件 def request(flow): flow.request.headers['User-Agent'] = 'MitmProxy' print(flow.request.headers) ``` ② cmd输入`mitmdump -s scripts.py`,即指定脚本scripts.py来处理截获的数据;`mitmdump -w 文件名`(把截获的数据保存到文件中);`mitmdump -p 8099` (指定监听端口) ```python mitmdump -s scripts.py -p 8080 ``` `scripts.py脚本执行效果`:在浏览器和手机分别打开[http://httpbin.org/get](http://httpbin.org/get) * 控制台端显示如下:控制台输出了修改后的Headers内容,其User-Agent的内容时mitmproxy 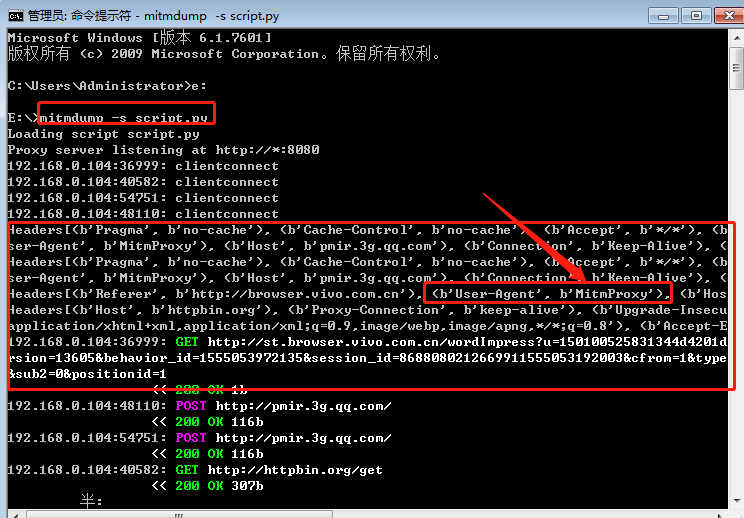 手机端显示如下:手机端返回的结果的Headers实际上就是请求头的Headers,User-Agent被修改成了MitmProxy 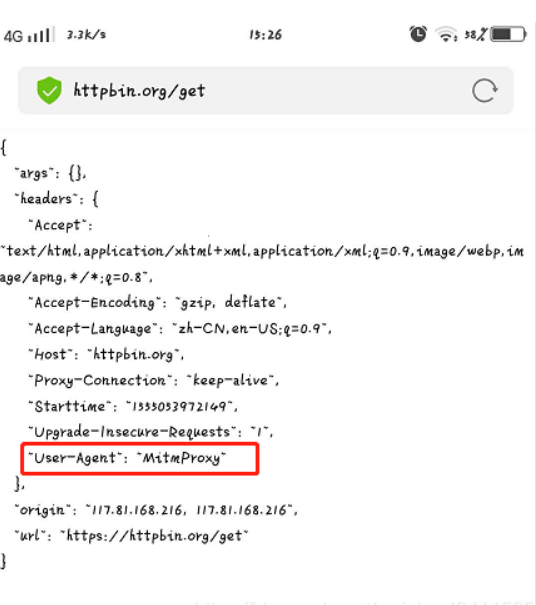 ## 3、mitmdump_python脚本日志输出 * mitmdump有专门的日志输出功能,可以设定不同级别以不同颜色输出结果,我们把scripts.py脚本修改成如下内容。主要调用了ctx模块的log功能(warning级别最高) ```python from mitmproxy import ctx def request(flow): flow.request.headers['User-Agent'] = 'MitmProxy' ctx.log.info(str(flow.request.headers)) # 白色 ctx.log.warn(str(flow.request.headers)) # 黄色 ctx.log.error(str(flow.reuquest.headers)) # 红色 ``` warning级别最高,如控制台打印如下  ## 4、mitmdump_request请求常用功能 [更多属性详见](http://docs.mitmproxy.org/en/latest/scripting/api.html),如下编辑scripts.py脚本如下,我们可以对以下任意属性进行修改赋值 ```python from mitmproxy import ctx def request(flow): request = flow.request # 如修改url flow.request.url = 'https:..httpbin.org/get' info = ctx.log.info info(str(request.headers)) info(str(request.cookies)) info(request.host) info(request.method) info(str(request.port)) info(request.scheme) ``` ## 5、mitmdump_response响应常用功能 * mitmdump对应的响应处理接口是response()方法,如下新编辑的scripts.py脚本,可以获取每个请求的响应内容,并对响应的信息提取和存储,即完成爬取 ```python from mitmproxy import ctx def response(flow): response = flow.response info = ctx.log.info info(str(response.status_code)) info(str(response.headers)) info(str(response.cookies)) info(str(response.text)) ``` 或者 ```python from mitmproxy import ctx # 所有发出的请求数据包都会被这个方法所处理 # 所谓的处理,我们这里只是打印一下一些项;当然可以修改这些项的值直接给这些项赋值即可 def request(flow): flow.request.headers['User-Agent'] = 'Mozilla/5.0 (Linux; Android 7.1.1; MI 6 Build/NMF26X; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/6.2 TBS/043807 Mobile Safari/537.36 MicroMessenger/6.6.1.1220(0x26060135) NetType/WIFI Language/zh_CN' # 获取请求对象 request = flow.request # 实例化输出类 info = ctx.log.info # 打印请求的url info(request.url) # 打印请求方法 info(request.method) # 打印host头 info(request.host) # 打印请求端口 info(str(request.port)) # 打印所有请求头部 info(str(request.headers)) # 打印cookie头 info(str(request.cookies)) def response(flow): response = flow.response info = ctx.log.info info(str(response.status_code)) info(str(response.headers)) info(str(response.cookies)) info(str(response.text)) ``` 6、mitmdump_实战案例 * 应用场景:当无法进行逆向分析某个加密参数时,可以按此法拦截请求爬取数据 * 流程步骤: * 编写处理逻辑py文件scripts.py > 后台长期启动`mitmdump -s scripts.py`捕获拦截存储等 * 其中捕获数据需要自动化的操作,如果是web端可以借助selenium等长期进行翻页,然后scripts.py监控处理。 * 如果是app端,则可以借助appium等长期翻页,然后scripts.py监控处理,但是appium与手机过于麻烦,也可以借助模拟器,然后纯adb命令操作等 * [mitmdump_实战demo1](https://blog.csdn.net/weixin_43411585/article/details/89276072?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164231299716780271980021%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164231299716780271980021&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-2-89276072.nonecase&utm_term=mitmdump&spm=1018.2226.3001.4450) * [mitmdump_实战demo2](https://blog.csdn.net/weixin_43411585/article/details/106087010?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164231406716781685381821%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164231406716781685381821&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-3-106087010.nonecase&utm_term=appium&spm=1018.2226.3001.4450) 参考博客:[十一姐](https://blog.csdn.net/weixin_43411585?type=blog) 待补充:https://blog.csdn.net/lyshark_lyshark/article/details/125848208 最后修改:2024 年 07 月 13 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
