Loading... ### 二、网站调试分析 ### 搜索关键字  搜索内容失败,说明弹幕被乱码或者加密了 ### 官方提供了api接口 > 要想获取某个视频的弹幕,只需要将该视频的cid代入上述链接即可 ### 获取cid ```py https://www.bilibili.com/video/BV1B3411f7J6/?spm_id_from=333.1007.tianma.1-2-2.click&vd_source=86f5553eab8c76f70bbe6fb7cd9eebb1 #先用正则去获取页面里面的cid "baseUrl":"https://xy125x75x230x184xy.mcdn.bilivideo.cn:4483/upgcxcode/51/74/901217451/901217451-1-30112.m4s? #901217451就是cid ``` ### 用cid获取弹幕xml `https://comment.bilibili.com/901217451.xml` **代码** ```python url = f'http://comment.bilibili.com/{ cid}.xml'#指定cid headers = { 'referer': 'https://www.bilibili.com/video/BV19h411s7oq?spm_id_from=333.934.0.0', 'User-Agent': 'https://www.bilibili.com/video/BV19h411s7oq?spm_id_from=333.934.0.0', 'cookie': "_uuid=19DF1EDB-20B7-FF74-A700-9DF415B2429530977infoc; buvid3=AAD6C6C7-FB31-40E7-92EC-7A6A7ED3920C148814infoc; sid=jzp2723t; fingerprint=2e74a5bc11a3adec2616987dde475370; buvid_fp=AAD6C6C7-FB31-40E7-92EC-7A6A7ED3920C148814infoc; buvid_fp_plain=AAD6C6C7-FB31-40E7-92EC-7A6A7ED3920C148814infoc; DedeUserID=434541726; DedeUserID__ckMd5=448fda6ab5098e5e; SESSDATA=1fe46ad7%2C1651971297%2Ceb583*b1; bili_jct=5bcd45718996ac402a29c7f23110984d; blackside_state=1; rpdid=|(u)YJlJmmu|0J'uYJYRummJm; bp_t_offset_434541726=590903773845625600; bp_video_offset_434541726=590903773845625600; CURRENT_BLACKGAP=0; LIVE_BUVID=AUTO5716377130871212; video_page_version=v_old_home; PVID=1; CURRENT_FNVAL=976; i-wanna-go-back=1; b_ut=6; b_lsid=4F7CFC82_17D78864851; bsource=search_baidu; innersign=1" } resp = requests.get(url, headers = headers) print(resp.text) ``` 成功获取到了数据但是全部都是乱码,这里我们不用设置字符的编码格式, 只需要让request获取到的编码格式和网页的编码格式相等即可 调用.encoding属性获取requests模块的编码方式 调用.apparent_encoding属性获取网页编码方式 将网页编码方式赋值给response.encoding ```py resp.encoding = resp.apparent_encoding ``` ## 信息提取 数据已经给成功的获取到,接下来我们要提取出所有的弹幕信息, 我们从获取到网站的响应信息后可以看出,所有的弹幕文字信息其实都是在标签之内的  ### 使用正则提取 ```py # 获取所有评论内容 content_list = re.findall('<d p=".*?">(.*?)</d>', resp.text) ``` ### 数据保存 我们使用函数将所有的弹幕数据存储在’B站弹幕.csv’文件中 ```python if os.path.exists(comment_file_path): os.remove(comment_file_path) for item in content_list: with open(comment_file_path, 'a', encoding = 'utf-8')as fin: fin.write(item + '\n') print(item) print('-------------弹幕获取完毕!-------------') ``` ## 数据处理 接下来就是对数据去重和去空处理了,然后随机抽取五条数据展示如下: ```text # 读取数据 rcv_data = pd.read_csv('./B站弹幕.csv', encoding='gbk') # 抽样展示5条数据 print(rcv_data.sample(5)) 精彩弹幕 538 一脸开心 162 好活 661 买两箱,,买买买买 17 笑死我了 哈哈哈 424 不忘初心 ``` ### 词频展示 文章评论出现频率最高的前十个词分别如下: ```python # 词频设置 all_words = [word for word in result.split(' ') if len(word) > 1 and word not in stop_words] wordcount = Counter(all_words).most_common(10) ''' ('哈哈哈', '大爷', '制作', '离谱', '一起', '猝不及防', '二仙', 'sir', '卧槽', '一定') (207, 69, 27, 13, 13, 13, 12, 12, 12, 9) ''' ``` 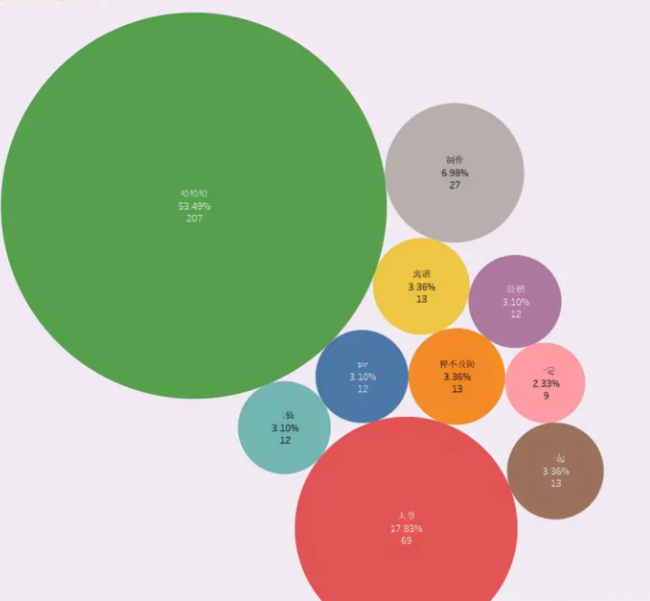 ### 词云展示 我们使用结巴分词,绘制什么图片看你选择,一定是白色背景 最后使用stylecloud绘制漂亮的词云图展示 ```python # 词云展示 def visual_ciyun(): pic = './img.jpg' gen_stylecloud(text=result, icon_name='fas fa-archway', font_path='msyh.ttc', background_color='white', output_name=pic, custom_stopwords=stop_words ) print('词云图绘制成功!') ```  所有代码 ```python # -*- coding: utf-8 -*- # Date: 2021/12/2 10:00 # Author: 不卖萌的邓肯 # wechat: 印象python import requests import re, os import jieba from wordcloud import WordCloud from imageio import imread comment_file_path = 'B站弹幕.csv' def spider_page(cid): url = f'http://comment.bilibili.com/{ cid}.xml' headers = { 'referer': 'xxxxx', 'User-Agent': 'xxxxx', 'cookie': "xxxxx" } resp = requests.get(url, headers = headers) # 调用.encoding属性获取requests模块的编码方式 # 调用.apparent_encoding属性获取网页编码方式 # 将网页编码方式赋值给response.encoding resp.encoding = resp.apparent_encoding print(resp.text) if resp.status_code == 200: # 获取所有评论内容 content_list = re.findall('<d p=".*?">(.*?)</d>', resp.text) if os.path.exists(comment_file_path): os.remove(comment_file_path) for item in content_list: with open(comment_file_path, 'a', encoding = 'utf-8')as fin: fin.write(item + '\n') print(item) print('-------------弹幕获取完毕!-------------') def data_visual(): with open(comment_file_path, encoding='utf-8')as file: comment_text = file.read() wordlist = jieba.lcut_for_search(comment_text) new_wordlist = ' '.join(wordlist) mask = imread('img_1.png') wordcloud = WordCloud(font_path='msyh.ttc', mask=mask).generate(new_wordlist) wordcloud.to_file('picture_1.png') if __name__ == '__main__': cid = '901217451' print('正在解析,开始爬取弹幕中。。。。。') spider_page(cid) #data_visual() ``` 记得点赞哦![O5O]RLQ`]SB0J0010O]Q6JH.jpg](http://type.zimopy.com/usr/uploads/2022/12/1977297100.jpg) 最后修改:2022 年 12 月 02 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
